안녕하십니까, 힘법사입니다. 이번 글은 적응형 허프만 코딩에 대한 글입니다. 직접 게시물과 마찬가지로 제가 보고서를 작성하면서 만든 코드와 보고서 내용을 통해 게시물을 작성했습니다! 해당 내용은 굉장히 이론 자체는 쉬웠는데 솔직히 구현하는데 8시간 정도 들만큼 조금 애를 먹은 것 같습니다... 하지만 어떻게든 만들어 내니 뿌듯하네요 ㅎㅎ 아쉬운 점은 Node 구조체에 제가 탐색의 편의를 위해서 부모 노드의 주소를 가지고 있는 포인터 변수를 하나 넣었는데 이거 말고 노드의 번호를 넣어서 구현했으면 어떗을까 조금 아쉽네요(유튜브를 보니 전부 노드의 번호를 이용해주더라고요) 먼저 코드 주소부터 올리겠습니다. 파일은 간단하게 헤더파일 하나가 올라가있습니다.
2017103030/Adaptive-Huffman-Coding: 적응형 허프만 코딩 헤더 파일입니다. (github.com)
GitHub - 2017103030/Adaptive-Huffman-Coding: 적응형 허프만 코딩 헤더 파일입니다.
적응형 허프만 코딩 헤더 파일입니다. Contribute to 2017103030/Adaptive-Huffman-Coding development by creating an account on GitHub.
github.com
I. 코드의 목적
Adaptive Huffman coding 구현과 이해
적응형 허프만 코딩(Adaptive Huffman coding)은 허프만 코딩을 기반으로한 Adaptive coding 기법이다. 허프만 코딩의 경우 확률 테이블이 없다면 수행이 불가능 하지만 적응형 허프만 코딩의 경우 사전에 데이터에 대한 초기 정보 없이도, 데이터들이 전송되고 이는 중에도 계속해서 코드를 생성해 나갈 수 있다는 장점이 있다 그렇기 때문에. 실시간(real-time)시스템에서 인코딩 용으로 활용하기 매우 적합하다.
실습에서는 이러한 적응형 허프만 코딩을 구현해 적용해보았을 때 한 심볼을 1byte로 잡았을 때와 비교해서 얼마나 데이터가 줄어들 수 있는지 확인해볼 수 있다.
II.과정
1. node 구조체
코드는 노드 구조체를 사용한다. 노드 구조체는 심볼, 빈도, 코드, 자식 노드의 주소들, 그리고 부모 노드의 주소로 구성된다. 해당 구조체에 대한 구체적인 설명은 표1에 나타내었다. 여기서 조금은 특별한 값은 부모 노드의 주소를 가지고 있는 parent 값이다. 사실 자식 노드의 주소들만으로 전체 구조를 표현하여도, 전체적인 트리의 구조를 파악할 수 있지만, 적응형 허프만 코딩에서는 자식 노드의 변화에 따라 부모노드의 상태가 매우 적극적으로 그리고 동적으로 변화하기 때문에 더 편리하고 빠른 탐색을 가능하도록 하기 위해서 해당 값을 넣어주었다.
| 변수 | 설명 |
| characters : string | 심볼 즉 대표하는 문자를 담고 있다. |
| frequency : unsigned int | 현재까지 해당 심볼의 빈도를 저장한다. |
| code : string | 코드를 저장한다. |
| leftChild : node* | 왼쪽 자식노드의 주소를 저장한다. |
| rightChild : node* | 오른쪽 자식노드의 주소를 저장한다. |
| parent : node* | 부모 노드의 주소를 저장한다. |
2. 함수들
함수는 총 9개로 크게, 전체 인코딩을 관장하는 함수, 노드의 상태와 위치를 변화시키는 함수군, 노드의 탐색과 검사를 진행하는 함수군으로 나눠져있다.
함수들에 대한 구체적인 서명과 설명은 표2에 나타내었다. 해당 함수들 중 가장 중요한 함수는 get_adaptive_huffman_code() : void 으로 해당 함수에서 모든 논리 순서와 동작을 제어하고 서버처럼 다른 함수들을 불러서 사용한다.
또 다른 특이 사항으로는 모든 탐색과 관련된 함수는 내부에서 큐(Queue) 자료구조를 이용해주며 BFS(Breadth first search, 넓이 우선 탬색) 알고리즘을 사용해서 동작하게 된다. BFS를 사용한 이유는 탐색을 빨리 종료하게 하기 위함과, 트리에서 노드의 깊이를 알 필요있기 때문이다.
| 함수 | 설명 |
| SwapNode(node*,node*) : void | 입력받은 두 노드의 위치를 바꿔준다. |
| findnode(node*,string): node* | 원하는 심볼의 트리내 주소를 반환해준다. 탐색 알고리즘은 BFS로 수행된다. |
| SearchDepth(node&,string) : int | 트리에서 찾고자 하는 심볼의 깊이를 반환한다. 찾지못할 경우 –1을 반환해준다. 탐색은 BFS로 이뤄진다. |
| UpdateFrequency(node *) : void | 입력받은 노드의 주소로부터 트리 상단으로 노드의 빈도 수 값을 갱신한다. |
| CheckTree(node&,node*vector<string>,vector<int>) : void | 트리 내부의 상하 관계를 파악한다. 더 깊은 곳에 있는 노드의 빈도수가 더 얕은 곳에 있는 노드의 빈도수보다 높다면 이를 바로 수정해준다. |
| AssignCode(node*): void | 트리 전체의 code를 위치에 따라 업데이트 해준다. |
| CheckTree2(node *) : void | 부모 노드의 자식 간의 관계를 검사한다. 왼쪽 자식 노드가 오른쪽 자식 노드보다 빈도수가 높은 사실이 확인 이를 바로잡아준다. |
| Print(node *, const vector, const vector) : void | 트리 전체의 코드를 출력해주는 함수다 |
| get_adaptive_huffman_code() : void | 자기 자신을 제외한 8개의 함수를 호출하고 관리하는 함수다. 궁극적으로 적응형 허프만 코딩이 동작하도록 관리한다. |
표 2 적응형 호프만 코딩을 위한 함수들
3. 적응형 허프만 코딩의 동작
3-1 루트 노드 초기화
처음 프로그램이 동작하면 루트 노드를 생성하고 해당 노드에 NEW 노드에 해당하는 값인 빈도수0과 심볼에는 해당 노드가 NEW임을 알려주기 위해 NEW 값을 적어준다. 그리고 가리키는 다른 노드들이 없기 때문에 전부 NULL로 초기화 시킨다.
3-2 사용자 입력 단계
사용자로부터 받은 심볼을 검사하는 단계다. 지금까지 입력으로 들어온 이력을 관리하는 배열인 vector<string> charst을 검색해 해당 심볼이 이전에 없던 심볼이라면 A를 수행한다. 만약 이력이 있는 심볼이면 B를 수행한다. quit이 입력되면 종료한다.

A. 트리에 존재하지 않는 심볼이 입력으로 들어왔을 경우
해당 경우 NEW 노드가 현재 트리 상 어디에 있는지 탐색한다. 해당 과정은 findnode 함수를 통해서 수행되고, NEW 노드를 찾을 때 까지 BFS 알고리즘을 계속해서 수행한다.
NEW 노드를 찾게 되면 기존의 NEW 노드는 또 하나의 부모 노드로 정보를 업데이트 해주고 해당 부모 노드 아래에 새로운 NEW 노드와 새 심볼 노드를 생성한다.

해당 과정을 보여주는 것이 그림2로 보게 되면 새로운 빈도수 0의 NEW 하나와 기존에 없던 심볼 A를 생성한 모습이다.

이에 대한 프로그램 출력 결과는 그림3과 같다. 그림3은 모든 리프노드(Leaf Node)를 출력하도록 한 것인데, 리프노드가 두 개 생성된 것을 확인할 수 있다.
B. 트리에 존재하는 심볼이 입력으로 들어왔을 경우
해당 경우 findnode 함수를 통해 BFS 알고리즘으로 해당 심볼이 트리 내 어디 존재하는지 탐색을 진행한다. 탐색을 끝마치고 나면, 해당 주소의 노드의 빈도수를 1만큼 올려준다.
3-3 트리 빈도수 갱신 및 검사 단계
앞선 단계와 같이 하위 노드를 만들어주거나 노드들의 상태를 변화시켜주면, 이와 연관된 상위의 노드들의 빈도수 값 또한 변해야한다. 이 과정은 UpdateFrequency 함수를 이용해 수행된다. 그림4는 이 과정을 잘 보여주고 있다. 그림4의 StepI처럼 두 자식노드에 변화가 생기게 되면, 이를 바로 그 상위 부모노드인 x의 빈도수 값을 결정짓게 하고 이는 다시 그 부모 노드 y에 영향을 줘 빈도수 값을 8로 만들게 된다.

빈도수를 갱신하고 나면, 트리의 규칙이 깨질 수 있다. 이 때 트리의 규칙이 깨졌는지 검사를 하는 단계를 실행 해야한다. 검사는 두 종류를 실시한다.
a) 트리의 노드들은 상하관계에 따라 더 상위에 있는 노드들이 빈도수가 같거나 높아야한다.
b) 트리의 노드들은 항상 오른쪽 자식 노드가 왼쪽 자식 노드의 빈도수 보다 같거나 커야 한다.
우선 a를 위해서 모든 심볼들의 깊이와 빈도수를 검사한다. 깊이 검사는 BFS로 이뤄지게 되고 깊이 검사 결과 상위 심볼들 보다 더 빈도수가 높은 심볼이 탐지되게 되면 두 노드들의 위치를 바꿔준다. 해당 과정은 SwapNode함수로 수행되게 된다. 상하 관계 검사를 CheckTree 함수를 통해 마치게 되면 수평관계를 검사한다. 이는 b의 규칙을 위반했는지 확인하는 검사로 CheckTree2 함수로 이뤄진다. 검사 과정은 루트로부터 모든 노드들을 검사해 가며 b를 어기는 노드가 있다면 SwapNode를 통해 규칙을 다시 바로잡아 준다.
3-4 코드 할당 단계
해당 단계는 AssignCode 함수를 이용해 수행된다. 수행은 매우 간단하다.

그림 5와 같이 왼쪽 자식 노드에는 0을 오른쪽 자신 노드에는 1을 할당해줘가며 모든 리프노드에 대해서 코드를 할당하도록 한다. 이 과정을 끝내면 다시 3-2단게로 돌아가 반복한다.
III. 결론
이렇게 구성된 적응형 허프만 코딩 알고리즘의 수행결과를 보도록 하겠다. 테스트할 메시지는 AADCCDD이며 예상되는 결과는 그림6과 같은 트리고, 결과는 표4와 같이 나올 것으로 기대할 수 있다.
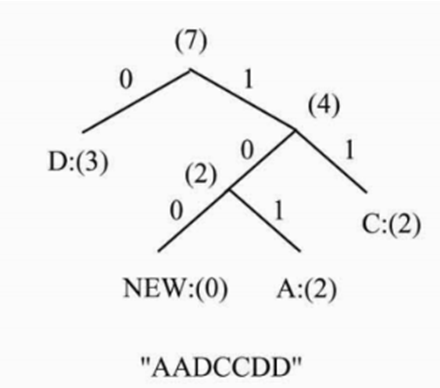
| 심볼 | 코드 |
| A | 101 |
| D | 0 |
| C | 11 |
| NEW | 100 |
표4 예상되는 결과 표
이에 대한 전체 입력 과정은 그림7에 나타내었다. 전체 과정이 잘 이뤄졌고 결과를 확인해보면, 표4의 예상 결과와 시스템이 만들어낸 결과가 동일한 것을 확인할 수 있다.

만약 해당 경우 AADCCDD 메시지를 모두 ASCII 코드로 보낸다고 가정했을 시 7Byte 즉, 56 bit가 소모되는 것을 알 수 있다. 하지만 시스템을 통해 적응형 호프만 코딩을 해본 결과 A는 3bit, D는 1bit, C는 2bit로 13bit만이 소모되는 것을 알 수 있다. 이는 데이터량이 4.31배 차이나는 결과로 이를 통해 실제 적응형 허프만 코딩을 하는 것이 매우 유용한 것을 알 수 있다.
'C && C++' 카테고리의 다른 글
| 동영상 캡쳐 프로그램 (C++/Opencv) (0) | 2022.01.06 |
|---|---|
| [C++] 이진트리(binary tree) 전위 순회, 중위 순회, 후위 순회, 레벨 순서 순회 (0) | 2021.11.12 |
| [C++] DCT / IDCT / Quantization / De-Quantization 코드 (0) | 2021.11.10 |
| [C++] Arithmetic Coding(산술 부호화) (0) | 2021.10.12 |
| OpenCV 설치하기(C++) (0) | 2021.04.30 |